

Transformers: A Comprehensive Guide for Beginners and Professionals
The world of Artificial Intelligence (AI) is constantly evolving, with new breakthroughs emerging at a rapid pace. One such innovation that has significantly impacted the field, particularly in Natural Language Processing (NLP), is the Transformer architecture. Since their introduction in 2017, Transformers have revolutionized how we approach tasks involving sequential data, such as text and speech. They have proven to be highly effective and versatile, surpassing traditional methods like Recurrent Neural Networks (RNNs) in many areas.
The power of Transformers lies in their ability to process information in parallel, allowing for faster training and the ability to capture long-range dependencies within sequences. This has led to significant improvements in tasks like machine translation, text summarization, question answering, and even creative content generation. Think about applications like Google Translate achieving greater accuracy or AI assistants like Bard and LLaMA 3 engaging in more natural and coherent conversations - all thanks to the advancements brought about by Transformers.
Understanding the Fundamentals
To truly grasp the power of Transformers, we need to understand the core concepts that underpin their architecture. Two fundamental ideas are key to their success: the Attention Mechanism and the Encoder-Decoder structure. Let's break down each of these concepts:
A. Attention is All You Need:
The heart of a Transformer lies in its attention mechanism. This innovative approach allows the model to focus on specific parts of the input sequence that are most relevant to the task at hand. Imagine you're listening to a conversation in a crowded room. You naturally focus your attention on the speaker's words, filtering out the background noise. Similarly, the attention mechanism enables the Transformer to identify and prioritize the most important words or phrases within a sentence or paragraph.
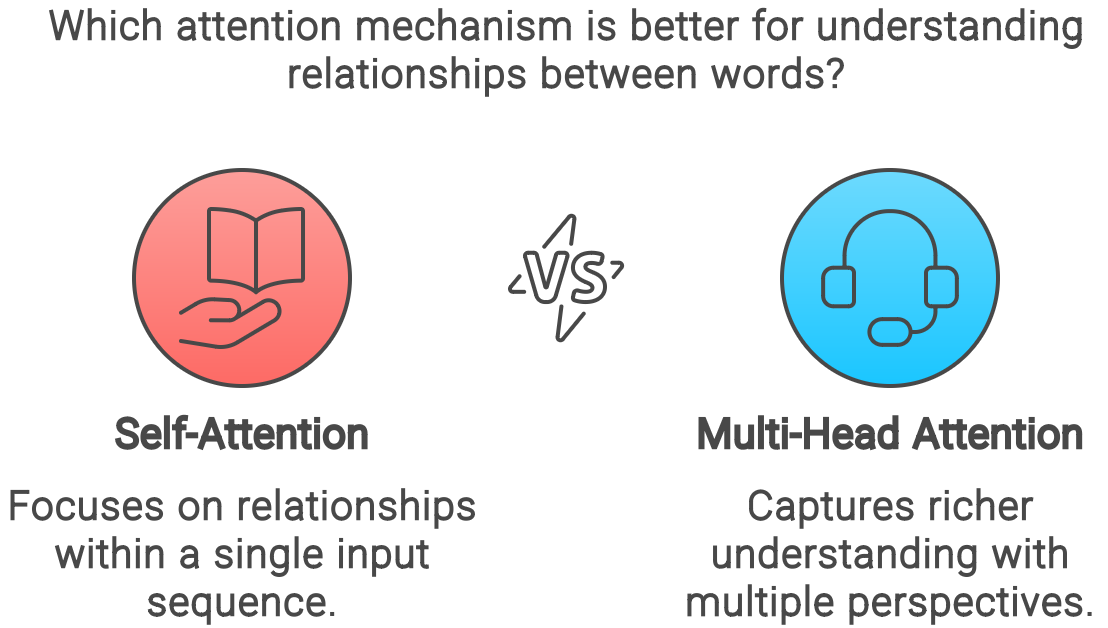
- Self-Attention: This type of attention allows the model to attend to different parts of the same input sequence. For instance, in the sentence "The cat sat on the mat," self-attention helps the model understand the relationship between "cat" and "sat" by focusing on these words within the context of the entire sentence.
- Multi-Head Attention: This mechanism expands on self-attention by allowing the model to attend to different parts of the input sequence simultaneously and in multiple ways. Think of it like having multiple perspectives on the same sentence, allowing the model to capture a richer understanding of the relationships between words.
B. The Encoder-Decoder Structure:
Transformers typically employ an encoder-decoder structure. This structure enables the model to process input sequences and generate corresponding output sequences.
- Encoder: The encoder's role is to analyze the input sequence and transform it into a meaningful representation. It does this by applying multiple layers of self-attention and feed-forward networks, extracting important features and relationships from the input data.
- Decoder: The decoder takes the encoded representation from the encoder and uses it to generate the output sequence. It also employs attention mechanisms, but unlike the encoder, it can attend to both the encoded input and its own partially generated output. This allows the decoder to generate coherent and contextually relevant sequences.
Visualizing the Data Flow:
Imagine a pipeline where the input sequence flows into the encoder, which then processes it and passes a condensed representation to the decoder. The decoder then uses this information to generate the desired output sequence. Diagrams and flowcharts can be invaluable in visualizing this process and understanding how data moves through the different components of a Transformer.
Emoji Transformer Pipeline
Experience the magic of a simplified Transformer model! Select a phrase from the dropdown and watch as it's transformed into emojis. This visualization demonstrates how data flows through the Encoder and Decoder in a Transformer pipeline.
Encoder
Waiting for input...
Decoder
Waiting for encoder...
Output
Waiting for decoder...
Exploring the Inner Workings - A Simplified Explanation
We've covered the basics of Attention and the Encoder-Decoder structure. Now, let's peek inside the Transformer and see how these parts work together. Think of this section as looking under the hood of a car - we won't be mechanics, but we'll understand the key parts.
A. Positional Encoding: Knowing Word Order Matters
Imagine reading a sentence backward. It wouldn't make much sense! Transformers need to know the order of words, just like we do. Positional Encoding is like giving each word a numbered ticket based on its place in the sentence. This helps the Transformer understand the context and meaning.
B. Feed-Forward Networks: Refining the Information
After the attention mechanism highlights the important words, the Feed-Forward Network steps in. Think of it as a filter that refines the information, making it clearer and more useful for the Transformer to understand.
Feed-Forward Network Refinement
Observe how a Feed-Forward Network (FFN) in a Transformer model refines information after the attention mechanism. Enter a sentence and watch as the FFN processes and enhances the output, making it clearer and more useful for the model to understand.
Attention Output
Waiting for input...
FFN Layer 1
Waiting for attention output...
FFN Layer 2
Waiting for Layer 1 output...
Refined Output
Waiting for FFN processing...
C. Layer Normalization and Residual Connections: Keeping Things Stable
Training a complex model like a Transformer can be tricky. It's like building a tall tower – you need to make sure it's stable. Layer Normalization and Residual Connections act like supports for the tower, preventing it from wobbling or collapsing during the training process.
Building a Stable Transformer Model
Add layers to build your Transformer model. Toggle the supports to see how they affect stability!
How it works:
In this interactive model:
- Each block represents a layer in the Transformer model.
- The green supports on either side represent Layer Normalization and Residual Connections.
- As you add more layers, the model becomes more complex and potentially unstable.
- Removing the supports when the tower is tall will cause it to shake, illustrating the importance of these stabilizing techniques in deep learning models.
This visualization helps understand why Layer Normalization and Residual Connections are crucial in training deep Transformer models.
In Simple Terms:
- Positional Encoding: Tells the Transformer the order of words.
- Feed-Forward Networks: Refines the information for better understanding.
- Layer Normalization and Residual Connections: Keep the training process stable and efficient.
Think of these components as working together like a well-coordinated team. The attention mechanism highlights important information, the feed-forward network refines it, and layer normalization and residual connections ensure everything runs smoothly. This teamwork allows Transformers to process information effectively and achieve impressive results in various tasks.
Applications of Transformers
Transformers have emerged as a powerful tool with a wide range of applications across various fields. Their ability to process sequential data effectively has led to significant advancements in Natural Language Processing (NLP) and beyond. Let's explore some of the key areas where Transformers are making a real-world impact:
A. Natural Language Processing (NLP):
Transformers have revolutionized NLP, enabling machines to understand and generate human language with remarkable accuracy and fluency. Here are some notable examples:
- Text Generation: Transformers excel at generating human-quality text, making them ideal for tasks like:
- Machine Translation: Accurately translating text from one language to another, as seen in Google Translate.
- Text Summarization: Condensing lengthy articles or documents into concise summaries.
- Conversational AI: Powering engaging and coherent conversations with AI assistants like Bard and LLaMA 2.
- Question Answering: Transformers can extract precise information from vast amounts of text to answer specific queries, facilitating efficient research and knowledge retrieval.
- Sentiment Analysis: By analyzing text, Transformers can determine the emotional tone and intent behind it, valuable for understanding customer feedback, social media sentiment, and market trends.
B. Beyond NLP:
The versatility of Transformers extends beyond NLP, demonstrating their potential in diverse fields:
- Computer Vision: Transformers are being applied to tasks like image recognition, object detection, and even image generation, pushing the boundaries of what's possible in computer vision.
- Time Series Analysis: Analyzing sequential data like stock prices or weather patterns, Transformers can forecast trends and patterns, enabling better decision-making in finance, meteorology, and other fields.
- Bioinformatics: Transformers are showing promise in complex tasks like protein structure prediction and drug discovery, potentially accelerating advancements in healthcare and medicine.
The Impact of Transformers:
The widespread adoption of Transformers across these diverse fields highlights their transformative power. From enhancing communication and understanding to driving scientific discovery, Transformers are shaping the future of AI and its applications in numerous domains. As research and development continue, we can expect to see even more innovative uses of this versatile architecture, unlocking new possibilities and pushing the boundaries of what AI can achieve.
Applications of Transformers
Transformers have emerged as a powerful tool with a wide range of applications across various fields. Their ability to process sequential data effectively has led to significant advancements in Natural Language Processing (NLP) and beyond. Let's explore some of the key areas where Transformers are making a real-world impact:
A. Natural Language Processing (NLP):
Transformers have revolutionized NLP, enabling machines to understand and generate human language with remarkable accuracy and fluency. Here are some notable examples:
- Text Generation: Transformers excel at generating human-quality text, making them ideal for tasks like:
- Machine Translation: Accurately translating text from one language to another, as seen in Google Translate.
- Text Summarization: Condensing lengthy articles or documents into concise summaries.
- Conversational AI: Powering engaging and coherent conversations with AI assistants like Bard and LLaMA 3.
- Question Answering: Transformers can extract precise information from vast amounts of text to answer specific queries, facilitating efficient research and knowledge retrieval.
- Sentiment Analysis: By analyzing text, Transformers can determine the emotional tone and intent behind it, valuable for understanding customer feedback, social media sentiment, and market trends.
B. Beyond NLP:
The versatility of Transformers extends beyond NLP, demonstrating their potential in diverse fields:
- Computer Vision: Transformers are being applied to tasks like image recognition, object detection, and even image generation, pushing the boundaries of what's possible in computer vision.
- Time Series Analysis: Analyzing sequential data like stock prices or weather patterns, Transformers can forecast trends and patterns, enabling better decision-making in finance, meteorology, and other fields.
- Bioinformatics: Transformers are showing promise in complex tasks like protein structure prediction and drug discovery, potentially accelerating advancements in healthcare and medicine.
The Impact of Transformers:
The widespread adoption of Transformers across these diverse fields highlights their transformative power. From enhancing communication and understanding to driving scientific discovery, Transformers are shaping the future of AI and its applications in numerous domains. As research and development continue, we can expect to see even more innovative uses of this versatile architecture, unlocking new possibilities and pushing the boundaries of what AI can achieve.
Limitations of Transformers
While Transformers have demonstrated remarkable capabilities and revolutionized various fields, they are not without their limitations. Understanding these constraints is crucial for researchers and practitioners to make informed decisions about their application and development. Here are some key limitations to consider:
A. Computational Cost:
Training large Transformer models can be extremely resource-intensive, requiring significant computational power and specialized hardware like GPUs or TPUs. This high computational cost can be a barrier for individuals or organizations with limited resources, potentially hindering broader accessibility and experimentation.
Think of it like this: Training a large Transformer model is like fueling a rocket – it requires a tremendous amount of energy and specialized equipment. While the results can be impressive, the cost can be prohibitive for some.
B. Data Requirements:
Transformers typically require massive amounts of data to achieve optimal performance. This can be a challenge in domains where data is scarce or difficult to obtain. Insufficient data can lead to underfitting, where the model fails to generalize well to new, unseen examples.
Imagine this: Teaching a child a new language requires numerous examples and repetitions. Similarly, Transformers need vast amounts of data to learn complex patterns and relationships within language or other sequential data.
C. Interpretability:
Understanding the internal reasoning and decision-making processes of a Transformer can be challenging. The complex interactions within the attention mechanism and multiple layers make it difficult to interpret why a model arrives at a specific output. This lack of transparency can be a concern in applications where explainability and accountability are critical.
Consider this analogy: Trying to understand the inner workings of a complex machine with numerous interconnected parts can be daunting. Similarly, deciphering the decision-making process of a Transformer requires specialized tools and techniques.
Addressing the Limitations:
Despite these limitations, ongoing research and development efforts are actively exploring ways to address these challenges. Researchers are exploring techniques for more efficient training, reducing data requirements, and improving interpretability. As advancements continue, we can expect to see more accessible and transparent Transformer models, further expanding their potential and impact across various domains.
Conclusion
Transformers have undoubtedly revolutionized the field of Artificial Intelligence, particularly in Natural Language Processing. Their ability to process sequential data in parallel, coupled with the innovative attention mechanism, has enabled significant advancements in tasks like machine translation, text summarization, question answering, and more. Furthermore, their applications extend beyond NLP, impacting fields like computer vision, time series analysis, and bioinformatics.
This comprehensive guide has aimed to demystify the world of Transformers, providing a foundational understanding of their core concepts, inner workings, applications, and limitations. From the fundamental principles of attention and the encoder-decoder structure to the intricacies of positional encoding and feed-forward networks, we have explored the key components that contribute to the remarkable performance of these models.
While challenges such as computational cost, data requirements, and interpretability remain, ongoing research and development efforts are actively seeking solutions to overcome these limitations. As advancements continue, we can anticipate even more powerful and versatile Transformer models, further expanding their potential and impact across various domains.
Key Takeaways:
- Transformers have significantly advanced the field of AI, particularly in NLP.
- Their parallel processing capabilities and attention mechanism enable efficient and effective handling of sequential data.
- They have a wide range of applications, from text generation and question answering to image recognition and drug discovery.
- While challenges exist, ongoing research is paving the way for more accessible and transparent Transformer models.



