

Groq AI Chips: A Comparative Analysis of Processing Performance, Cost, and Power Consumption
 In the rapidly evolving world of artificial intelligence (AI), the hardware that powers these complex systems is crucial in determining their capabilities and efficiency. Two major players in the AI hardware market, Groq, and NVIDIA, have been pushing the boundaries of what's possible with their cutting-edge AI chips. This article aims to comprehensively analyze Groq's AI chips and NVIDIA's GPUs, focusing on processing performance, cost efficiency, and power consumption.
In the rapidly evolving world of artificial intelligence (AI), the hardware that powers these complex systems is crucial in determining their capabilities and efficiency. Two major players in the AI hardware market, Groq, and NVIDIA, have been pushing the boundaries of what's possible with their cutting-edge AI chips. This article aims to comprehensively analyze Groq's AI chips and NVIDIA's GPUs, focusing on processing performance, cost efficiency, and power consumption.
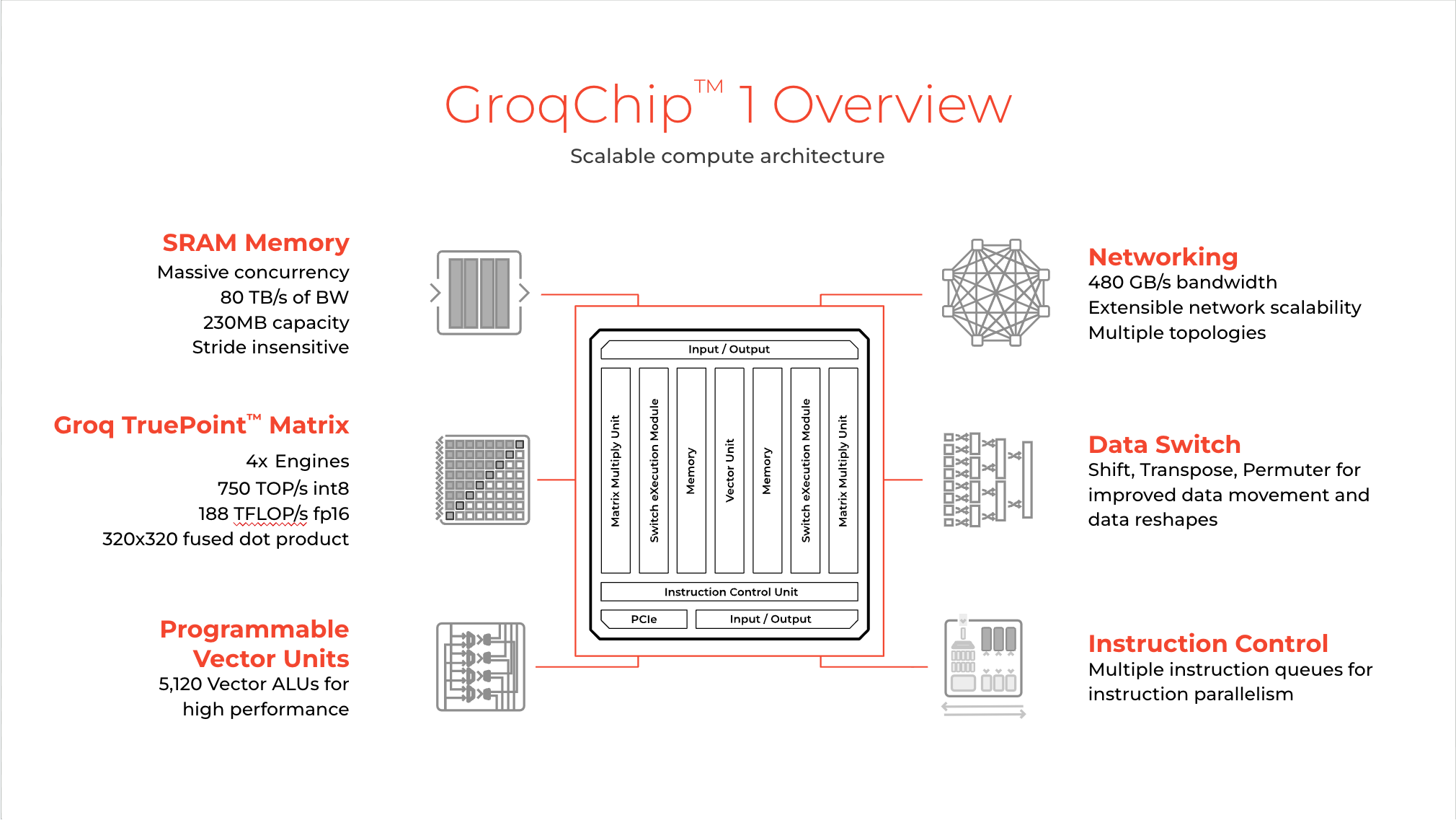
Comparative Analysis
Processing Performance
Groq's AI chips, specifically their Language Processing Units (LPUs), have demonstrated remarkable processing speed for AI tasks, particularly in large language models (LLMs). Some key performance metrics include:
- Groq's LPUs can achieve a throughput of up to 300 tokens per second for LLMs like Llama 3 70B.
- Groq's chips' latency is significantly lower than that of NVIDIA's GPUs, with a time to first token of only 0.2 seconds.
- Groq's chips can generate over 500 words in about one second, while NVIDIA's GPUs take nearly 10 seconds for the same task.
In comparison, while versatile and widely used, NVIDIA's GPUs struggle to match Groq's performance in specific AI tasks. For instance, NVIDIA's GPUs typically achieve a throughput of 10 to 30 tokens per second, significantly lower than Groq's LPUs.
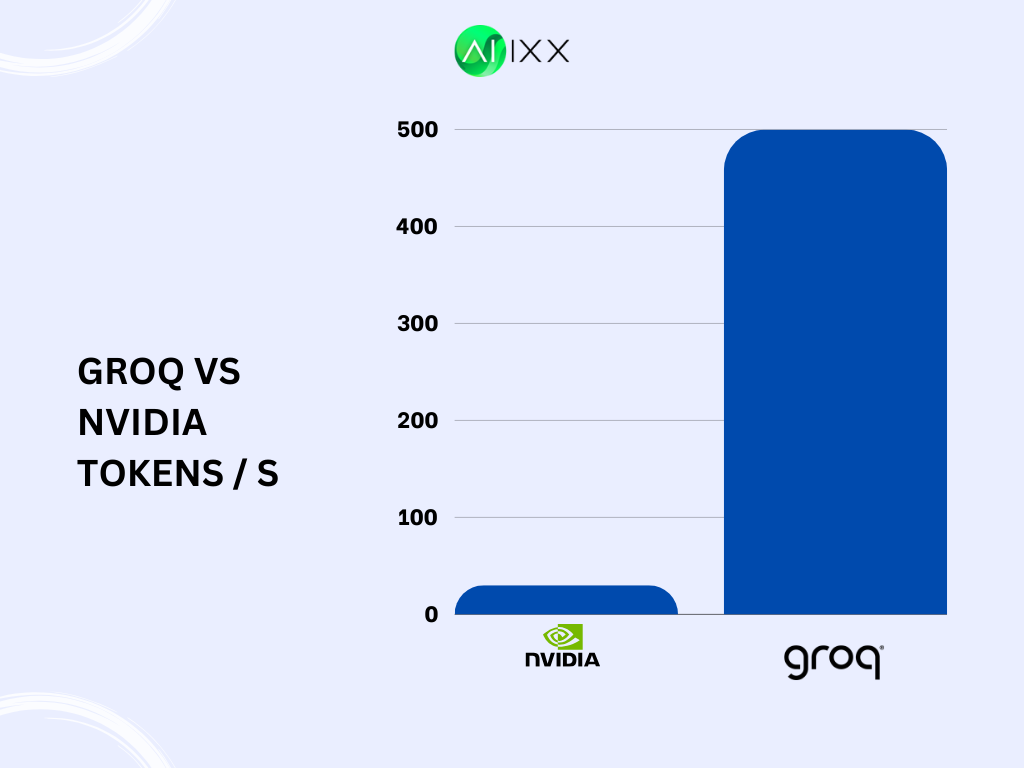
Cost Efficiency
While Groq's AI chips have a higher initial cost than NVIDIA's GPUs, they offer long-term cost efficiency due to lower power consumption and operational costs.
| Chip | Initial Cost | Tokens per Second (For LAMA 2 70B) |
|---|---|---|
| Groq LPU | $20,000 | 500 |
| NVIDIA A100 GPU | $10,000 | 30 |
As seen in the table above, although Groq's LPU has a higher upfront cost, its cost per token is significantly lower than NVIDIA's A100 GPU. This means that Groq's chips can provide better value in the long run for applications requiring high throughput and low latency.
Power Consumption
Groq's AI chips are designed to be highly energy-efficient, consuming significantly less power than NVIDIA's GPUs. This is achieved through Groq's unique architecture, which minimizes off-chip data flow and reduces the need for external memory.
Power Consumption Comparison
| Feature | Groq LPU | Nvidia A100 GPU |
|---|---|---|
| Max Power Consumption | GroqCard™: https://wow.groq.com/why-groq/ | Up to 400W |
| Average Power Consumption | GroqCard™: 240W | https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/PB-10577-001_v02.pdf |
| Setup Examples | GroqNode™: 4kW (8 cards) | 2048 A100 cards: Approx. 1000 kW |
| Chip-Level Consumption | 185W per chip | 250W per card (during LLaMa training) |
| Focus and Design Philosophy | Energy efficiency and cost-effectiveness | High performance for AI and HPC |
| Comparative Advantage | Lower power consumption; designed for energy efficiency | Higher power consumption reflective of high performance capabilities |
AI Task Simulator
How to use:
- Enter the number of tokens you want to process in the input field.
- Click the "Simulate" button to see how Groq LPU and NVIDIA A100 GPU compare in processing speed.
- The results will show the processing time for each chip and a visual representation of their relative speeds.
Use Cases and Applications
Groq's AI chips are particularly well-suited for real-time AI applications that require low latency and high throughput. Some potential use cases include:
- Interactive AI assistants and chatbots
- Real-time language translation
- Autonomous systems that require fast decision-making
While NVIDIA's GPUs remain versatile and widely used across various AI applications, they may not be the optimal choice for scenarios that demand the highest levels of speed and responsiveness.
Limitations of Groq's AI chips
There are a few key limitations of Groq's AI chips compared to other major AI hardware providers like NVIDIA and Intel:
Lack of on-chip high bandwidth memory (HBM):
- Groq's LPU chips do not have any on-chip HBM, relying instead on large amounts of on-die SRAM memory.
- In contrast, chips like NVIDIA's A100 GPU have up to 80GB of HBM2e memory with very high bandwidth.
- The lack of HBM may limit Groq's performance on larger models and batch sizes that require more memory capacity and bandwidth.
Uncertainty around software ecosystem and ease of use:
- As a much newer and smaller player, Groq's software ecosystem and developer tooling may not be as mature and widely adopted as NVIDIA's CUDA platform.
- The lack of a robust software ecosystem could make it harder for customers to adopt Groq and migrate workloads.
- Some of Groq's memory architecture terminology seems confusing and heavily trademarked compared to more standard terms used by other vendors.
Potential limitations in scaling beyond a single node:
- While Groq's architecture allows high scalability within a single server node or rack, it's unclear how well it scales out beyond that to multi-node clusters.
- Established interconnects like NVIDIA's NVLink and NVSwitch allow GPUs to scale efficiently to massive multi-node supercomputers and clusters.
- Groq must prove its chips can scale to the cluster and data center level as efficiently as alternatives.
Higher cost per chip:
- At nearly $20,000 per chip, Groq's LPU is significantly more expensive than a high-end GPU.
- The cost may be justified by the performance for certain workloads, but it could limit adoption to only the highest-value use cases.
- It's unclear if Groq has a cost/performance advantage at larger batch sizes that larger customers would use.



