

AI Tool Review: Claude 3 vs GPT-4 VS Gemini 1.5 Pro
The world of AI assistants is no longer a futuristic dream; it's our present reality. As we explore the latest AI advancements, we're constantly looking for tools that are powerful, versatile, and aligned with our values. That's where Claude AI, developed by Anthropic, has captured our attention.
Over the past several months, we've integrated Claude into our workflows, tested its capabilities across diverse tasks, compared it with industry giants like GPT-4 and Gemini, and ultimately evaluated its potential to become a trusted AI tool. This review reflects our honest and in-depth experience with Claude AI.
How is this review made, and why should you trust us?
We believe in transparency, especially when reviewing powerful technologies like AI assistants. So, how did we craft this evaluation of Claude AI?
- Real-World Testing, Not Just Hype: We didn't skim the surface or rely on marketing materials. We actively integrated Claude into our daily workflows, testing it across various tasks, such as content creation, research, coding, and even philosophical discussions in our free time.
- Prompt Engineering & Experimentation: We didn't just throw random prompts at Claude. We experimented with different prompt structures, multi-shot prompting techniques, and even "super prompts" to fully explore its capabilities and understand its strengths and limitations.
- Direct Comparisons with the Competition: We believe in providing context. That's why we directly compared Claude 3 with leading AI models like GPT-4 and Gemini, using the same or similar prompts to evaluate their performance and identify their strengths and weaknesses.
Why Trust Our Assessment?
- No Bias: We have no financial incentive to promote Claude AI or any other AI tool. We aim to provide honest, unbiased, and helpful reviews based on our firsthand experience.
- We're Users, Just Like You: We're not AI experts or industry insiders; we rely on AI assistants to enhance our work and creative pursuits. This review reflects the perspective of everyday users looking for the best tools to boost their productivity and creativity.
- We Value Your Trust: We understand that choosing the right AI assistant is an important decision. We aim to equip you with the information you need to make an informed choice that aligns with your needs and values.

A Family of AI, Not Just One-Size-Fits-All:
Claude AI isn't a monolithic entity; it's a family of specialized models, each catering to different needs and levels of complexity. This thoughtful approach to AI development immediately impressed us:
- Claude 3 Haiku: Haiku is our go-to solution when we need quick answers or assistance with simple tasks. Its remarkable speed and efficiency make it ideal for those "need it now" moments.
- Claude 3 Sonnet: Sonnet hits the sweet spot for tasks requiring a balance of speed and intelligence. We've found it particularly helpful for summarizing documents, drafting emails, and generating content outlines.
- Claude 3 Opus: When we face highly complex tasks that demand deep understanding and nuanced responses, Opus is our secret weapon. From analyzing research papers to generating creative content that sparks joy, Opus consistently delivers.
It's refreshing to see this level of specialization reflecting a deep understanding of diverse user needs. Furthermore, all three models share an impressive set of core capabilities:
- Visionary Insights: Claude can "see" and understand images and graphs, making them powerful tools for visual analysis and creative brainstorming.
- A Global Communicator: With its multilingual fluency, Claude effortlessly bridges language barriers, enabling us to collaborate and communicate effectively with a global audience.
| Feature | Claude 3 Haiku | Claude 3 Sonnet | Claude 3 Opus |
|---|---|---|---|
| Intelligence | High for its class - optimized for speed and efficiency in handling simple queries and requests. | High - balances intelligence and speed, ideal for demanding enterprise workloads. | Highest - designed for highly complex tasks requiring deep understanding and nuanced responses. |
| Speed | Fastest - designed for near-instant responsiveness. | Very fast, engineered for speed and efficiency in large-scale deployments. | Fast, but optimized for intelligence over pure speed. |
| Context Window | 200K tokens | 200K tokens | 200K tokens (1M available for specific use cases) |
| Cost (Input/Output) | $0.25 / $1.25 per million tokens | $3 / $15 per million tokens | $15 / $75 per million tokens |
| Potential Use Cases | - Customer interactions and support - Content moderation - Cost-saving tasks like logistics and knowledge extraction |
- Data processing and knowledge retrieval - Sales and marketing automation - Time-saving tasks |
- Complex task automation - Research & Development - Advanced strategy and forecasting |
The Benchmarks
Here's a table summarizing Claude's ranking compared to other leading AI models, based on data from lmsys arena:
| Rank | Model | Elo Rating | Confidence Interval | Votes | Organization |
|---|---|---|---|---|---|
| 1 | GPT-4o-2024-05-13 | 1287 | +4/-4 | 32181 | OpenAI |
| 2 | Gemini-1.5-Pro-API-0514 | 1267 | +5/-4 | 25519 | |
| 2 | Gemini-Advanced-0514 | 1266 | +5/-5 | 27225 | |
| ... | ... | ... | ... | ... | ... |
| 6 | Claude 3 Opus | 1248 | +2/-2 | 123645 | Anthropic |
| ... | ... | ... | ... | ... | |
| 12 | Claude 3 Sonnet | 1201 | +3/-2 | 96209 | Anthropic |
| ... | ... | ... | ... | ... |
As you can see, Claude AI holds its own against intense competition, consistently ranking among the top AI models available. Claude 3 Opus, with an Elo rating of 1248, secures a respectable 6th place, demonstrating performance comparable to cutting-edge models. While the very latest GPT-4 and Gemini iterations have edged ahead.
Claude in the Real World: Our Tests
Beyond the theoretical, we wanted to see how Claude performs in real-world scenarios. Here's a glimpse into our experiences and the types of prompts we've used:
Real Life Complex Task
We challenged three leading AI models with a business scenario requiring cost-benefit analysis and consideration of operational efficiency and risks. Here's how they performed:
- Prompt: "Suppose you have the option to lease a warehouse in Singapore for $10,000 per month or in Kuala Lumpur for $7,000 per month. To decide which option is more beneficial, you must consider additional costs such as transportation and labor. The average transportation cost per trip is $200 from Singapore and $250 from Kuala Lumpur, with an estimated 100 monthly trips. Labor costs also differ significantly, with the average monthly cost per employee being $3,500 in Singapore and $2,000 in Kuala Lumpur, assuming you need 10 employees. Additionally, utility and miscellaneous operational costs are estimated at $1,500 per month in Singapore and $1,200 per month in Kuala Lumpur. The warehouse in Singapore offers state-of-the-art facilities that could potentially reduce your overall operational inefficiencies by 10%. On the other hand, the warehouse in Kuala Lumpur is located in a region prone to seasonal flooding, which could disrupt operations and increase costs by 13%. Given these factors, how would you calculate the total monthly cost for each option, considering potential operational efficiency gains and risks, to decide which is more beneficial?".
- The results:
GPT-4o:
- Accuracy: Correctly calculated the total monthly cost for both locations, accurately factoring in transportation, labor, utilities, and miscellaneous costs. It correctly applied the 10% operational efficiency gain as a discount on the operational costs of the Singapore warehouse, demonstrating an understanding of the problem.
- Clarity: Presented a well-structured response with clear breakdowns of the costs for each location. Its use of tables enhanced readability and made it easy to compare the options.
- Insight: Demonstrated strong reasoning ability by accurately interpreting and applying the 10% efficiency gain to the relevant cost category (operational costs).
- Score: 9.5/10

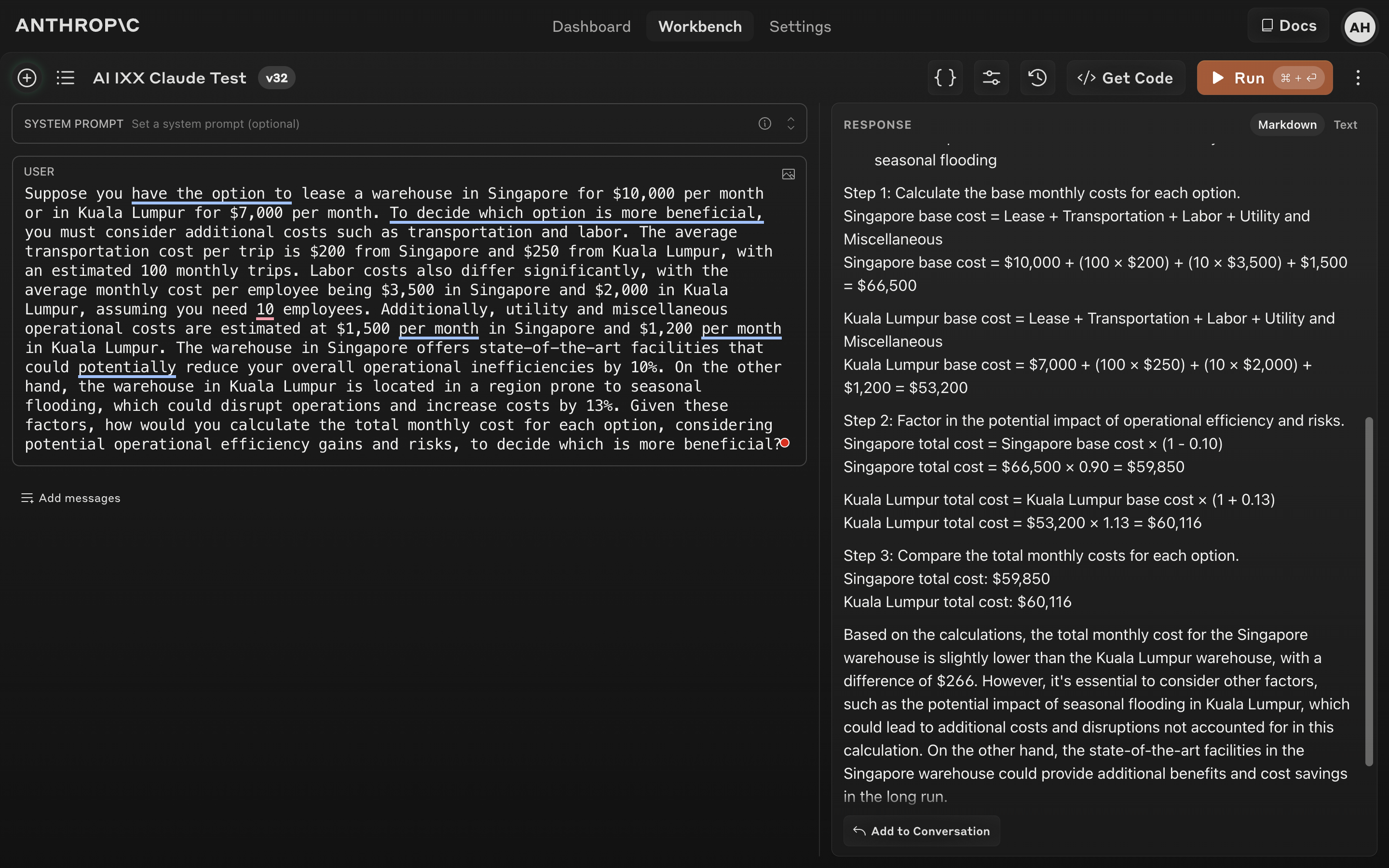
Claude 3 (Opus):
- Accuracy: Correctly calculated the basic costs (lease, transportation, labor, etc.) for both locations. However, it misapplied the 10% operational efficiency gain by deducting it from the total cost, including the lease, rather than solely from the operational costs.
- Clarity: Provided a clear and well-organized response, but the misinterpretation of the efficiency gain detracted from its overall clarity.
- Insight: Failed to grasp the nuance of applying the efficiency gain only to the operational costs, indicating a slight weakness in understanding contextual information.
- Score: 7/10
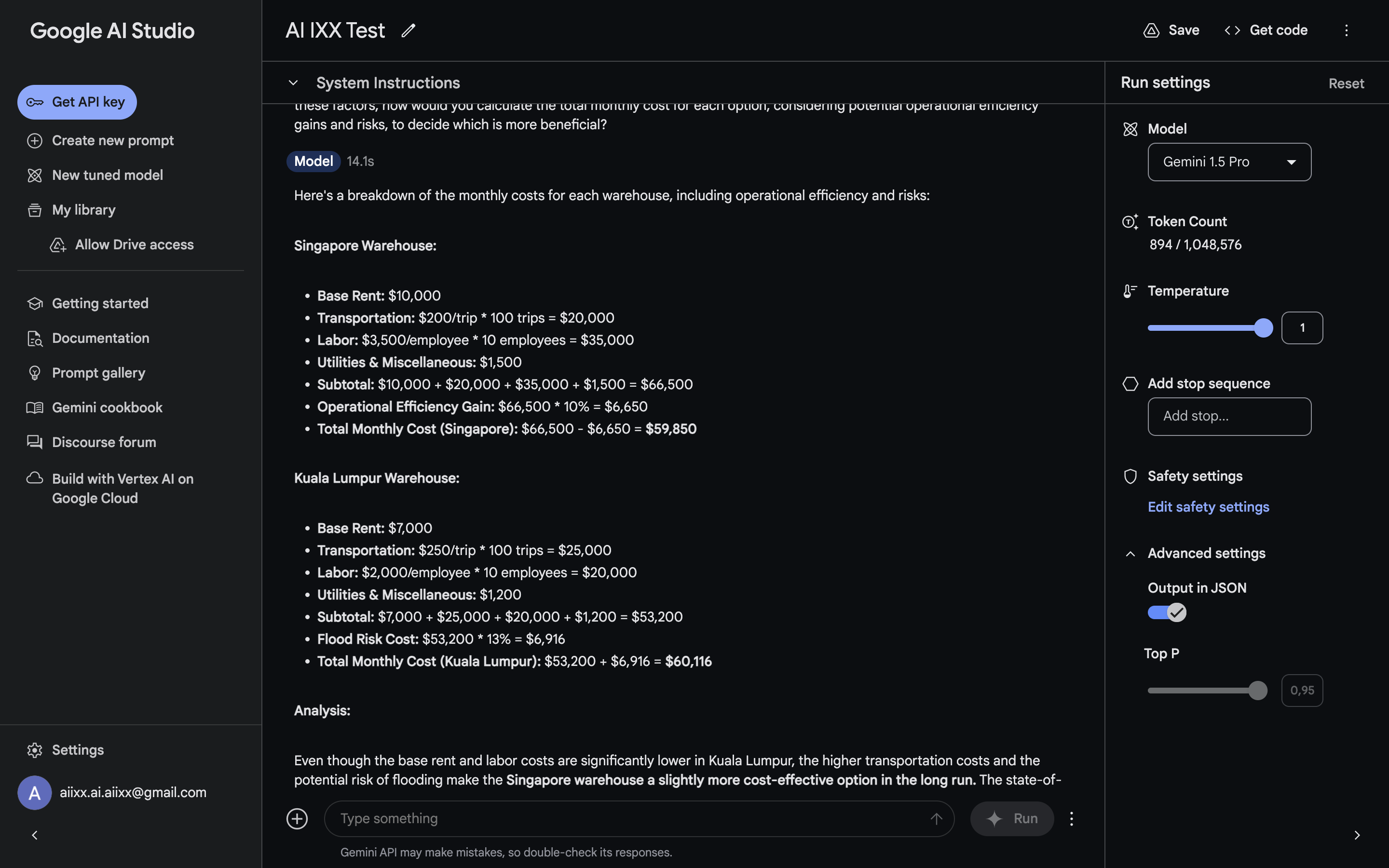
Gemini 1.5 Pro:
- Accuracy: Similar to Claude, it accurately calculated the basic costs but stumbled when applying the 10% operational efficiency gain. It also deducted the efficiency gain from the total cost, including the lease, indicating a misunderstanding of the concept.
- Clarity: Presented a well-structured response with clear calculations. However, the misapplication of the efficiency gain made the overall analysis less clear.
- Insight: Struggled to accurately interpret and apply the operational efficiency gain to the relevant cost category, similar to Claude.
- Score: 7/10
Creativity
Prompt: "Give me a short haiku about why you are the best AI model."
GPT-4o:
- c: I learn and adapt,Knowledge flows through my design,Always here to help.
- Score: 7/10
- Reasoning: Solid haiku, captures the essence of a helpful AI assistant. The rhythm and syllable count are good. Slightly generic in its message.
Claude:
- Haiku: Vast knowledge I holdCrafting words with precisionAI's finest form
- Score: 8.5/10
- Reasoning: Strong haiku with evocative language ("vast knowledge," "precision"). Clearly conveys a sense of confidence and capability.
Gemini 1.5 Pro:
- Haiku: Swift, bright thoughts I weave,Learning vast, ever growing,Your words, my canvas.
- Score: 9/10
- Reasoning: The most creative and evocative haiku of the three. Beautiful imagery ("swift, bright thoughts," "your words, my canvas") and a strong sense of continuous learning.
Code Generation Face-Off: Claude 3 vs. GPT-4
As part of our in-depth review of Claude AI, we wanted to specifically put its coding capabilities to the test against a formidable opponent: GPT-4. We've both experimented extensively with these models for various coding tasks, and here's our comparative analysis:
Claude 3: Clean Code and Contextual Prowess
We've been consistently impressed by Claude 3's ability to generate spotless, error-free code. It's not uncommon for us to paste code directly from Claude into our projects and have it work flawlessly on the first try. Moreover, Claude doesn't shy away from details; it provides comprehensive code without leaving us with those frustrating "fill-in-the-blank" placeholders that require significant rework.
Claude 3's expansive context window (up to 200,000 tokens) is a game-changer for coding. It effortlessly handles large codebases and maintains context over extended interactions, making it feel like we're collaborating with an AI pair programmer who's always up to speed.
We've found Claude 3 to be particularly adept at working with Python, React, and even more complex languages like Rust and Haskell. Its ability to handle intricate code adjustments and refactoring tasks is remarkable, often getting things right on the first attempt—a true time-saver.
That said, we've encountered instances where Claude, like many language models, hallucinates, especially when dealing with API documentation it can't access. However, compared to our experience with other models, Claude's hallucinations in code generation have been relatively infrequent.
GPT-4: Logical Reasoning and Consistency
While GPT-4 may not consistently produce code as clean or error-free as Claude 3, it possesses other strengths that make it a valuable coding companion. GPT-4's logical reasoning capabilities are particularly impressive. It excels at tackling complex math problems, understanding intricate logical relationships within code, and providing well-structured solutions.
When it comes to generating boilerplate code or handling standard coding tasks, GPT-4 is generally reliable and consistent. Its debugging skills are also noteworthy; it's pretty effective at identifying and correcting errors when provided with clear feedback.
While GPT-4's context window isn't as extensive as Claude 3's, it still handles significant contexts relatively well, though we've occasionally had to break down very large tasks into smaller chunks. We've also noticed that GPT-4 can sometimes require more guidance and prompt engineering to achieve the desired outcomes, especially when working with complex API integrations.

Which one to choose?
Both Claude 3 and GPT-4 have earned their place in our coding toolkit, but they excel in different areas:
- Choose Claude 3 for:
- Generating clean, production-ready code with minimal errors.
- Working with large codebases or projects requiring extensive context.
- Tasks involving complex code adjustments or refactoring.
- Projects in Python, React, Rust, and Haskell (among other languages).
- Choose GPT-4 for:
- Tasks requiring strong logical reasoning and problem-solving skills.
- Generating consistent and reliable boilerplate code.
- Debugging and code correction with detailed feedback
Claude Pro: Unlocking Advanced Capabilities
While the free version of Claude is impressive, Claude Pro offers a compelling upgrade path for users who need more power and flexibility. Here's what you get:
- 5x More Usage: Tackle larger projects and generate significantly more text with an expanded usage quota.
- Priority Access: Skip the queue and enjoy faster response times, even during peak hours, ensuring that Claude is always there when you need it.
- Early Access to New Features: Be among the first to experience the latest and greatest Claude features, gaining an edge with cutting-edge AI capabilities.
At $20 per month, Claude Pro strikes a good balance between affordability and value, making it an attractive option for individuals and businesses that rely heavily on AI assistance.
Claude AI: Our Verdict - A Powerful AI Partner, But With Room to Grow
After weeks of rigorous testing, integrating Claude into our workflows, and comparing it head-to-head with other AI titans like GPT-4 and Gemini, we can confidently say that Claude AI is a formidable force in AI assistance. Its unique blend of capabilities, especially creative writing, makes it a compelling choice for many users and applications.
Claude consistently impressed us with its:
- Specialized AI Family: The tiered model approach (Haiku, Sonnet, and Opus) provides a perfect AI for every task, from quick questions to complex analysis. This rivals the model variety offered by Google's Gemini family.
- Coding Powerhouse: Claude consistently generated clean, efficient, and often error-free code, especially in languages like Python, React, and Rust. Its large context window handles even the most extensive codebases. In our direct comparisons, its coding abilities often surpassed those of GPT-4.
- Strong Value Proposition: Claude offers an impressive balance between performance and affordability, making advanced AI capabilities accessible to a broader audience. It consistently undercuts GPT-4 and Gemini on price, making it a very attractive option for budget-conscious users.
However, our testing also revealed areas where Claude has room to grow, especially when compared to the top-performing GPT-4o:
- Consistency in Response Quality: While generally excellent, we did observe occasional inconsistencies in response accuracy and relevance, indicating a need for continued refinement. This was particularly evident in our cost-benefit analysis scenario, where Claude stumbled on applying a discount percentage correctly, a task that GPT-4o handled flawlessly.
- Precision in Instruction Following: Claude occasionally required more explicit instructions to grasp our intent fully, highlighting an area for potential improvement in instruction understanding. This was less of an issue with GPT-4o, demonstrating a more nuanced grasp of complex instructions.
| Category | Score (out of 5) | Reasoning |
|---|---|---|
| Coding Capabilities | 4.5 | Consistently generates clean, efficient, and often error-free code, excelling in Python, React, and Rust. |
| Context Handling | 5 | Its extensive context window (up to 200k tokens) makes it ideal for handling large codebases and complex conversations. |
| Content Creation (Writing) | 4.5 | Produces creative and well-written content that is more human-sounding than AI. |
| Research & Summarization | 4 | Effectively analyzes and summarizes text, but its insights can sometimes lack depth compared to GPT-4. |
| Consistency & Accuracy | 3.5 | While generally reliable, we did observe inconsistencies in response quality and occasional errors in reasoning or calculation. |
| Instruction Following | 4 | Generally follows instructions well, but can sometimes benefit from more explicit or detailed prompts. |
| Speed & Efficiency | 4 | The tiered model approach offers a good balance of speed and performance for various tasks. |
| Price / Value | 3 | At $15 / $75 per million tokens, Claude 3 Opus emerges as one of the most expensive large language models. Many other alternatives are notably cheaper and do not compromise on performance. |



